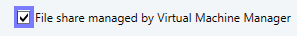![images1]()
Wir stoßen bei unserer Arbeit immer wieder auf die Situation, dass der Kunde bereits ein Hyper-V Failover Cluster und einen Scale-Out Files Server im Einsatz hat und diese beiden Systeme jetzt über den Virtual Machine Manager 2012 R2 verwalten möchte. Daher habe ich mich mit der Frage beschäftigt, welche Voraussetzungen notwendig sind, um einen bereits existierenden Scale-Out File Server (SOFS) im Virtual Machine Manager 2012 R2 hinzuzufügen und was dabei zu beachten ist.
Hier die Voraussetzungen, die bei uns in der Labor- und Produktivumgebung notwendig waren.
- Wir benötigen einen Domain Account der als RunAsAccount im Virtual Machine Manager 2012 R2 angelegt wird – er heißt z.b. SVMM-Admin. Es reichen hierfür die normalen Domain-Benutzer Berechtigungen im Active Directory aus.
- Dieser SCVMM-Admin darf nicht mit dem Service Account für den “System Center Virtual Machine Manager” Dienst identisch sein.
- Der SCVMM-Admin muss auf allen Hyper-V Hosts und auf allen Scale-Out File Server Knoten lokaler Administrator sein.
- Mit dem RunAsAccount des SCVMM-Admin muss das Hyper-V Failovercluster in den Virtual Machine Manager 2012 R2 hinzugefügt werden.
- Bei den SOFS-Freigaben müssen alle Hyper-V Hosts + das Hyper-V Clusterkonto einzeln (Gruppenberechtigungen funktionieren an dieser Stelle nicht) mit Vollzugriffsrechten berechtigt sein und auch der SCVMM-Admin benötigt Vollzugriffsrechte auf die SOFS-Freigaben.
- Die SMB Netze des Scale-Out File Servers sollten sie nicht in den DNS eintragen, da es sonst im Virtual Machine Manager 2012 R2 zu Problemen mit der Namesauflösung kommt.
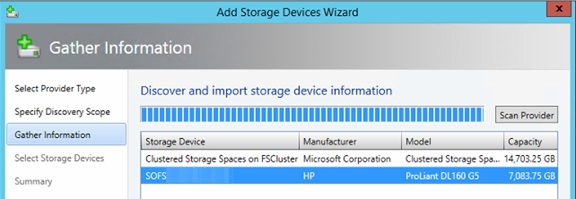
Sind diese Voraussetzungen alle gegeben, können wir das Scale-Out File Server Cluster im Virtual Machine Manager 2012 R2 hinzufügen.
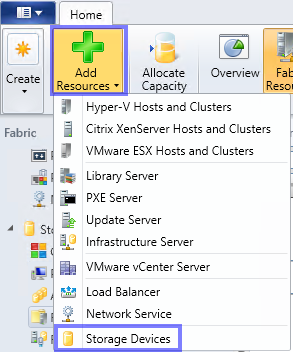
Dies kann über “Add Resources” oder aber unter “Fabric” “Storage” Rechtsklick “Add Storage Devices” erfolgen.
![]()
![]()
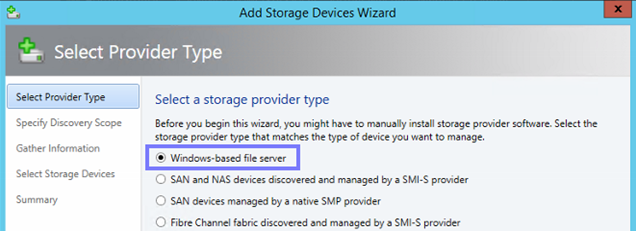
Hier wählen wir “Windows-based file Server” aus
![]()
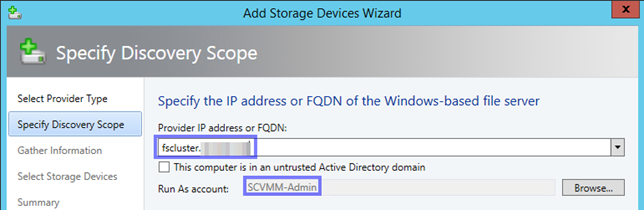
An dieser Stelle wird der FQDN des Scale-Out File Server Clusters eingegeben und der RunAsAccount ausgewählt, mit dem auch der Hyper-V Failover Cluster in den SCVMM hinzugefügt worden ist. In unsrem Fall der SCVMM-Admin.
![]()
![]()
![]()
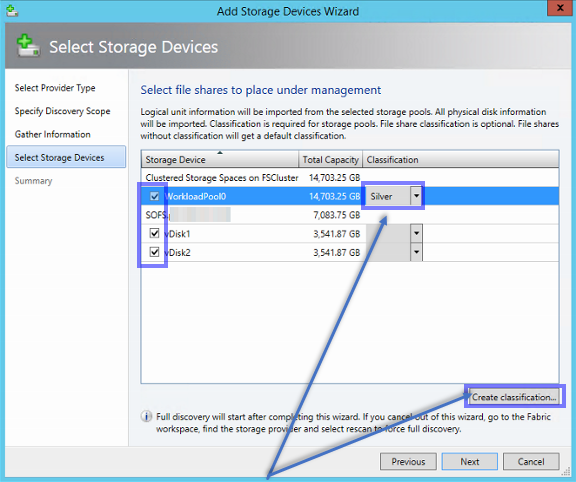
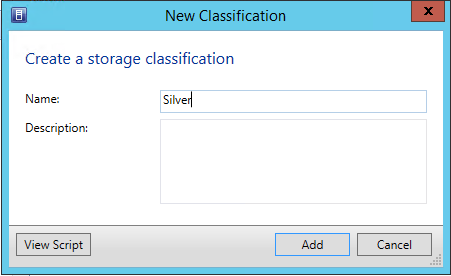
Für den Pool müssen wir eine Storage Classification angeben – diese können wir unter “Create classification” erstellen.
![]()
Es werden nur SOFS-Freigaben vom Virtual Machine Manager 2012 R2 verwaltet, wenn diese beim Hinzufügen auch ausgewählt werden. ACHTUNG!!! beim Entfernen des SOFS aus dem Virtual Machine Manager 2012 R2 – löscht der VMM bei allen verwalteten SOFS-Freigaben die Freigabe. Wenn dies nicht gewünscht ist, muss in den Eigenschaften jeder verwalteten SOFS-Freigabe der Hacken bei
![]()
entfernt werden.
Umgekehrt gilt, wenn Sie am SOFS weitere Applikationsfreigaben anlegen, werden diese nicht automatisch vom Virtual Machine Manager 2012 R2 verwaltet. Sondern erst, wenn in den Eigenschaften der Freigabe der Hacken bei “File share managed by Virtual Machine Manager” gesetzt wird. Erst dann kann diese SOFS-Freigabe auch dem Hyper-V Failover Cluster und jedem anderen Hyper-V Host zugeordnet werden.
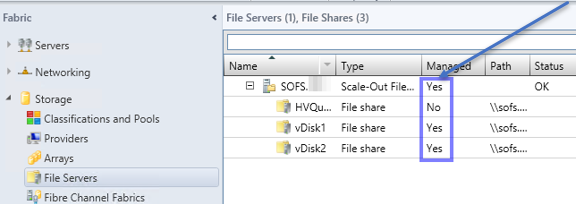
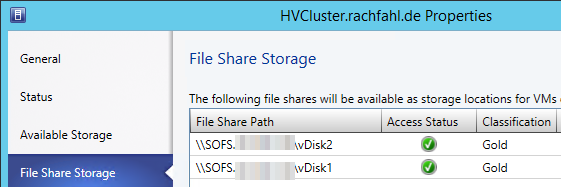
Hier können Sie überprüfen welche SOFS-Freigabe durch den Virtual Machine Manager 2012 R2 verwaltet wird.![]()
Jetzt kann den Hyper-V Hosts das Storage zugewiesen werden.
Handelt es sich hierbei um ein Hyper-V Failover Cluster, erfolgt dies in den Eigenschaften des Failover Clusters.
Bei den einzelnen Cluster Hosts ist die Möglichkeit unter Storage den File Share hinzu zufügen ausgegraut
![]()
Wir wählen also in den Hyper-V Failovercluster Eigenschaften “File Share Storage” aus und fügen die gewünschten SOFS-Freigaben hinzu. Es werden an dieser Stelle nur die SOFS-Freigaben angezeigt, die auch durch den VMM verwaltet werden!
![]()
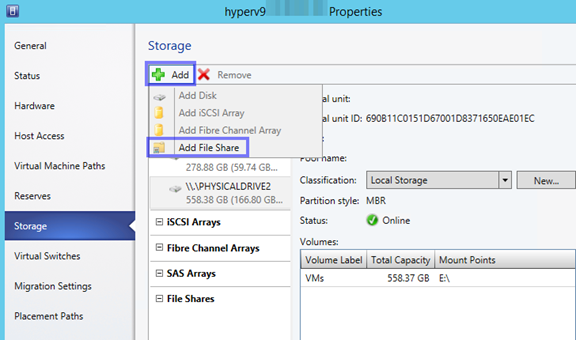
Soll einem einzelnen Hyper-V Host die SOFS-Freigabe zur Verfügung gestellt werden, so rufen Sie die Eigenschaften am Hyper-V Host auf und wählen “Storage” aus.
![]()
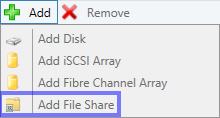
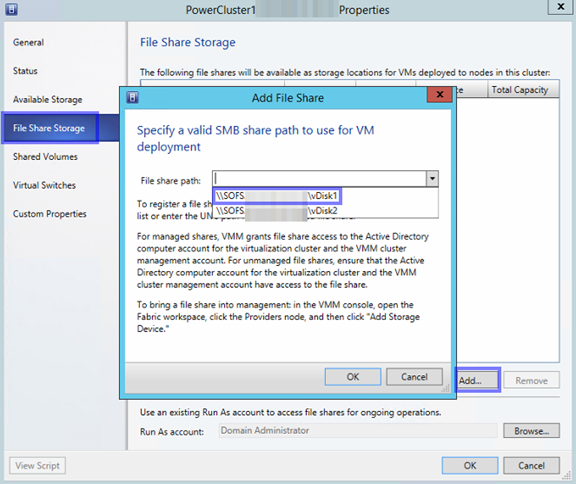
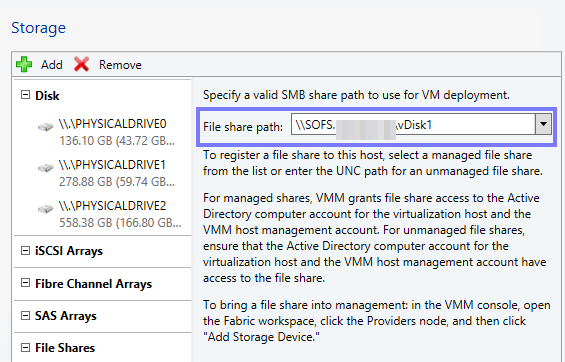
Hier kann über “Add” “Add File Share” aufgerufen werden. Jetzt kann rechts der Freigabe Pfad ausgewählt werden, mit “OK” bestätigen und schon steht auch diesem Hyper-V Host der Speicherplatz zur Verfügung – Voraussetzung hierfür ist, dass dieser Hyper-V Host im SBM Netz ist.
![]()
Wenn alles erfolgreich war, werden in den Hyper-V Failover Cluster Properties unter File Share Storage die Fileshares angezeigt
![]()
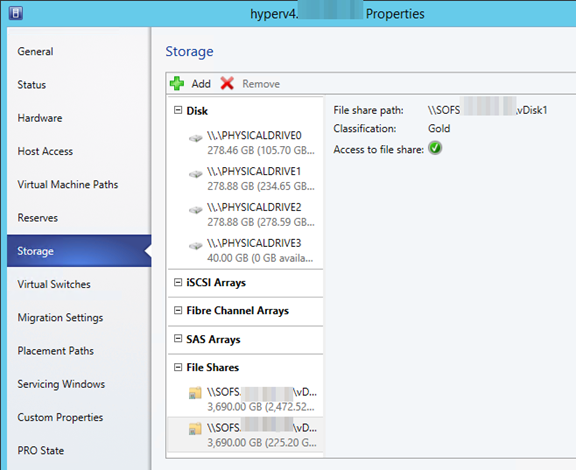
und auch an jedem Hyper-V Cluster Knoten unter Properties\Storage – File Shares.
![]()
Hier noch als Ergänzung die Powershell Befehle, mit denen eine SOFS-Freigabe als verwaltete Freigabe im Virtual Machine Manager 2012 R2 hinzugefügt werden kann.
$FileServer = Get-SCStorageFileServer -Name “FileServer01.Contoso.com”
$FileShare = Get-SCStorageFileShare -Name “FileShare01”
Set-SCStorageFileServer -StorageFileServer $FileServer -AddStorageFileShareToManagement $FileShare
Und wenn SOFS-Freigaben im Virtual Machine Manager nicht mehr verwaltet werden sollen, dann können folgende Powershell Kommandos abgesetzt werden.
$FileServer = Get-SCStorageFileServer -Name “FileServer01.Contoso.com”
$FileShare = Get-SCStorageFileShare -Name “FileShare01”
Set-SCStorageFileServer -StorageFileServer $FileServer -RemoveStorageFileShareFromManagement $FileShare
Quelle: Set-SCStorageFileServer
Der Beitrag Scale-Out File Server zum SCVMM 2012 R2 hinzufügen erschien zuerst auf Hyper-V Server Blog.


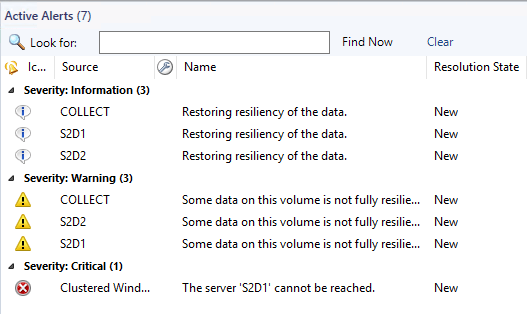

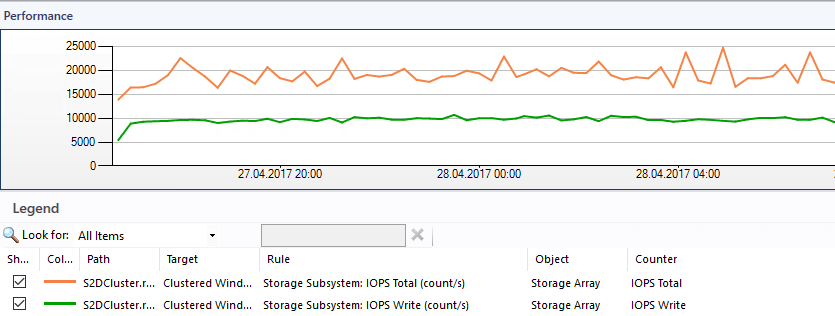

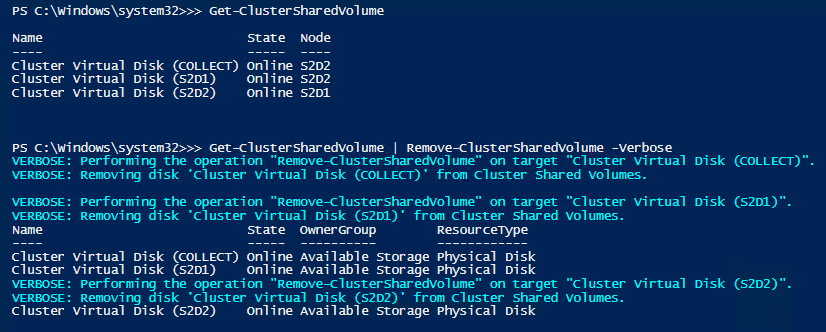



















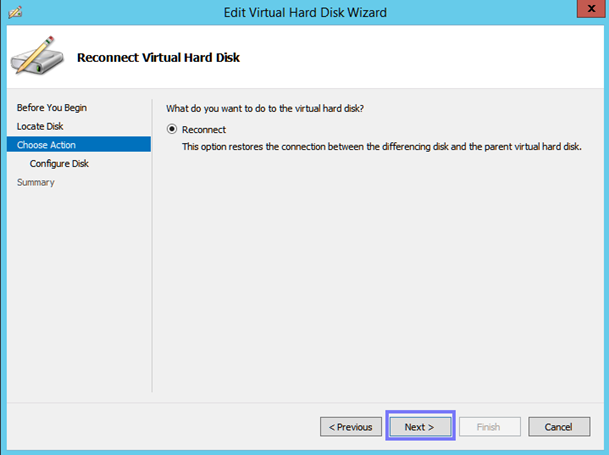
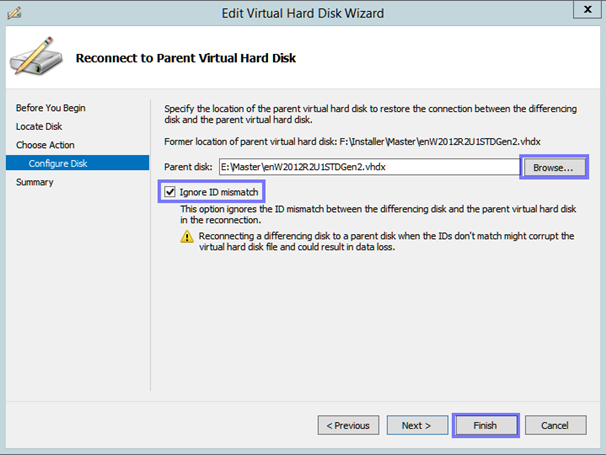
 Vor Kurzem stand ich vor der Aufgabe, die Pfade der Parent Disk für die Differencing Disks von VMs, anpassen zu müssen.
Vor Kurzem stand ich vor der Aufgabe, die Pfade der Parent Disk für die Differencing Disks von VMs, anpassen zu müssen.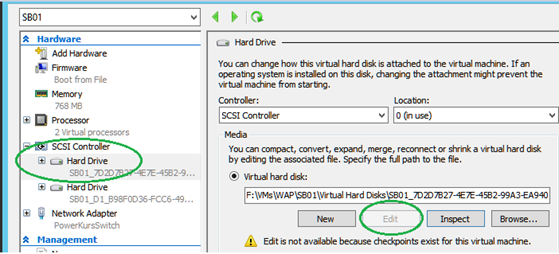
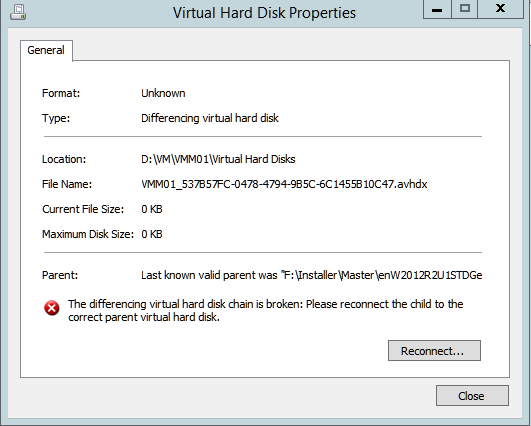
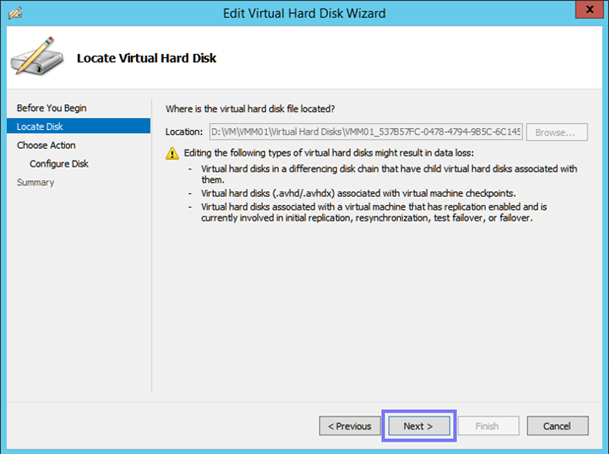
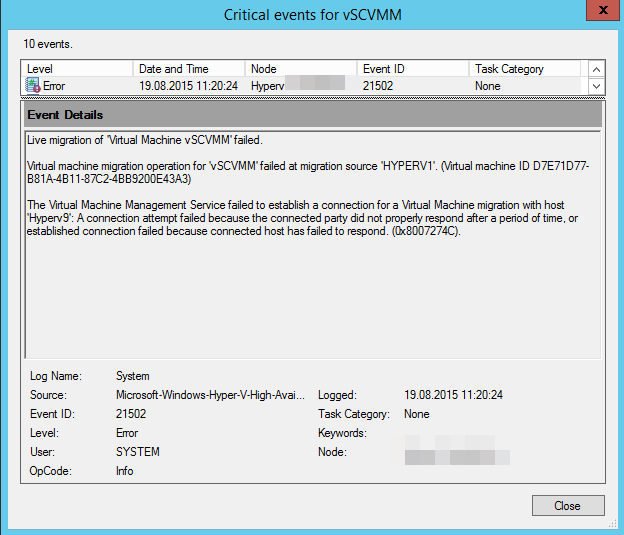
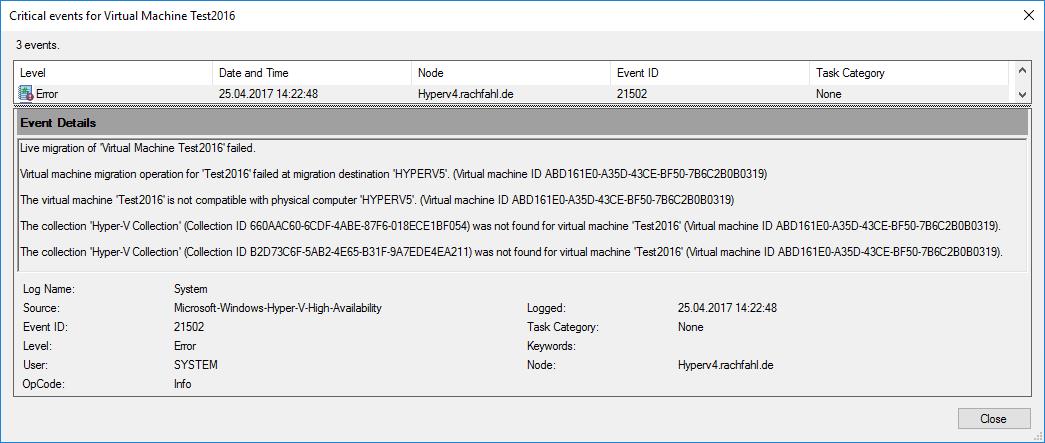
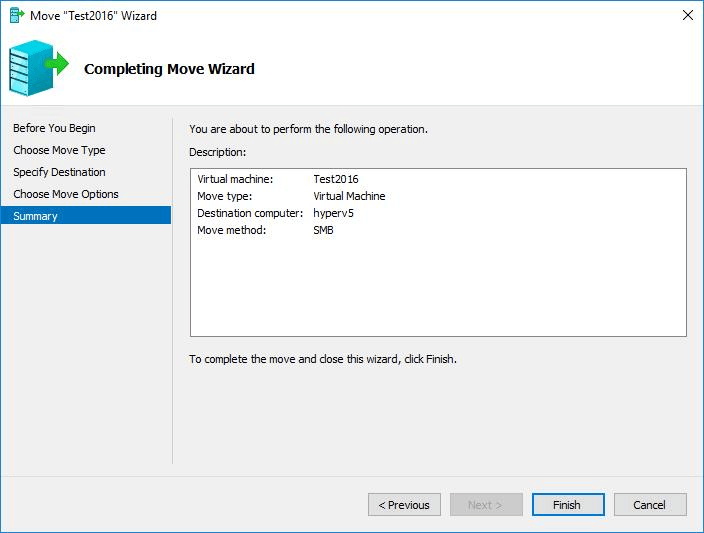
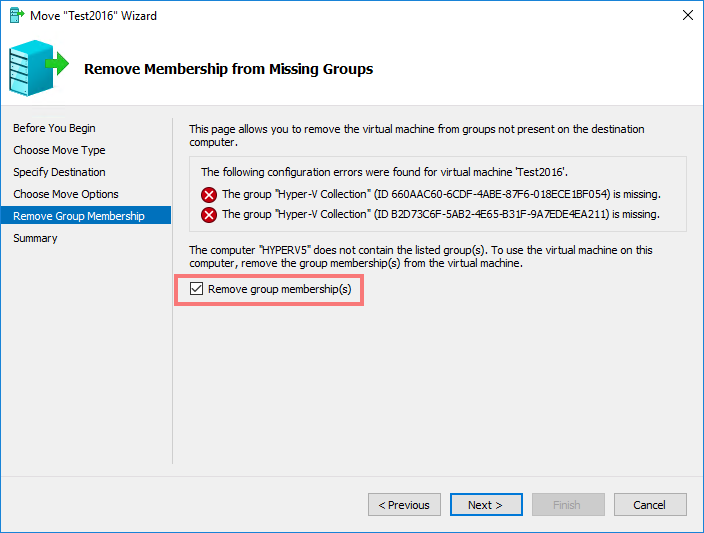
 Wir hatten heute bei unserem Hyper-V 2012 R2 Failovercluster das Problem, dass wir die Live Migration nur noch von einem Host aus durchführen konnten, beim zweiten Hyper-v Host bekamen wir folgende Fehlermeldung:
Wir hatten heute bei unserem Hyper-V 2012 R2 Failovercluster das Problem, dass wir die Live Migration nur noch von einem Host aus durchführen konnten, beim zweiten Hyper-v Host bekamen wir folgende Fehlermeldung: